

# 종속변수(RH)를 제외한 모든 컬럼을 StandatdScaler로 정규화 시킴
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_squared_error
ss = StandardScaler()
X =air_df.drop('RH', axis=1)
y = air_df['RH']
Xss = ss.fit_transform(X)
Xss

X_train, X_test, y_train, y_test = train_test_split(Xss, y, test_size=0.2, random_state=2024)
my_predictions = {}
colors = ['r', 'c', 'm', 'y', 'k', 'khaki', 'teal', 'orchid', 'sandybrown',
'greenyellow', 'dodgerblue', 'deepskyblue', 'rosybrown', 'firebrick',
'deeppink', 'crimson', 'salmon', 'darkred', 'olivedrab', 'olive',
'forestgreen', 'royalblue', 'indigo', 'navy', 'mediumpurple', 'chocolate',
'gold', 'darkorange', 'seagreen', 'turquoise', 'steelblue', 'slategray',
'peru', 'midnightblue', 'slateblue', 'dimgray', 'cadetblue', 'tomato']
def plot_predictions(name_, pred, actual):
df = pd.DataFrame({'prediction': pred, 'actual': y_test})
df = df.sort_values(by='actual').reset_index(drop=True)
plt.figure(figsize=(12, 9))
plt.scatter(df.index, df['prediction'], marker='x', color='r')
plt.scatter(df.index, df['actual'], alpha=0.7, marker='o', color='black')
plt.title(name_, fontsize=15)
plt.legend(['prediction', 'actual'], fontsize=12)
plt.show()
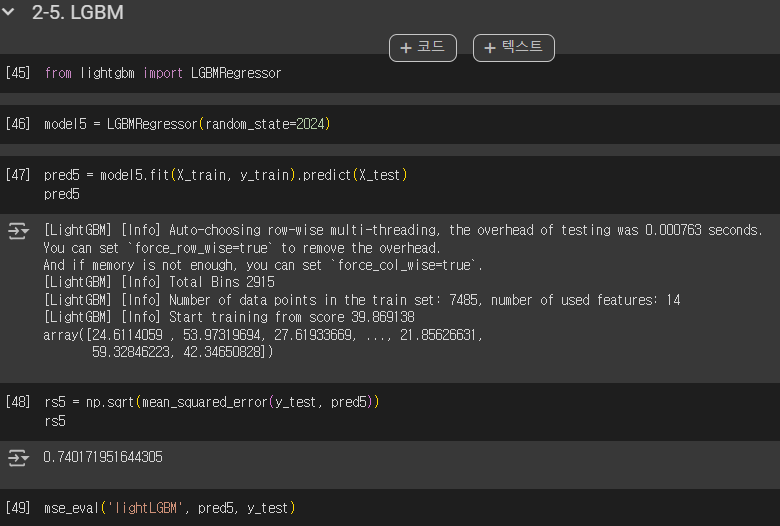
def mse_eval(name_, pred, actual):
global my_predictions
global colors
plot_predictions(name_, pred, actual)
mse = mean_squared_error(pred, actual)
my_predictions[name_] = mse
y_value = sorted(my_predictions.items(), key=lambda x: x[1], reverse=True)
df = pd.DataFrame(y_value, columns=['model', 'mse'])
print(df)
min_ = df['mse'].min() - 10
max_ = df['mse'].max() + 10
length = len(df)
plt.figure(figsize=(10, length))
ax = plt.subplot()
ax.set_yticks(np.arange(len(df)))
ax.set_yticklabels(df['model'], fontsize=15)
bars = ax.barh(np.arange(len(df)), df['mse'])
for i, v in enumerate(df['mse']):
idx = np.random.choice(len(colors))
bars[i].set_color(colors[idx])
ax.text(v + 2, i, str(round(v, 3)), color='k', fontsize=15, fontweight='bold')
plt.title('MSE Error', fontsize=18)
plt.xlim(min_, max_)
plt.show()








'딥러닝과 머신러닝' 카테고리의 다른 글
| Pytorch 선형회귀(2024-06-19) (1) | 2024.06.20 |
|---|---|
| KMean, Silhouette Score (2024-06-18) (0) | 2024.06.18 |
| lightGBM (2024-06-18) (0) | 2024.06.18 |
| Random Forest, 하이퍼파라미터, Feature Importances (0) | 2024.06.17 |
| Scaling, Normalization, Support Vector Machine (2024-06-12) (0) | 2024.06.17 |



