1. hotel 데이터셋
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 119390 entries, 0 to 119389
Data columns (total 32 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 hotel 119390 non-null object
1 is_canceled 119390 non-null int64
2 lead_time 119390 non-null int64
3 arrival_date_year 119390 non-null int64
4 arrival_date_month 119390 non-null object
5 arrival_date_week_number 119390 non-null int64
6 arrival_date_day_of_month 119390 non-null int64
7 stays_in_weekend_nights 119390 non-null int64
8 stays_in_week_nights 119390 non-null int64
9 adults 119390 non-null int64
10 children 119386 non-null float64
11 babies 119390 non-null int64
12 meal 119390 non-null object
13 country 118902 non-null object
14 distribution_channel 119390 non-null object
15 is_repeated_guest 119390 non-null int64
16 previous_cancellations 119390 non-null int64
17 previous_bookings_not_canceled 119390 non-null int64
18 reserved_room_type 119390 non-null object
19 assigned_room_type 119390 non-null object
20 booking_changes 119390 non-null int64
21 deposit_type 119390 non-null object
22 days_in_waiting_list 119390 non-null int64
23 customer_type 119390 non-null object
24 adr 119390 non-null float64
25 required_car_parking_spaces 119390 non-null int64
26 total_of_special_requests 119390 non-null int64
27 reservation_status_date 119390 non-null object
28 name 119390 non-null object
29 email 119390 non-null object
30 phone-number 119390 non-null object
31 credit_card 119390 non-null object
hotel_df.drop(['name', 'email','phone-number', 'credit_card', 'reservation_status_date'], axis=1, inplace=True)
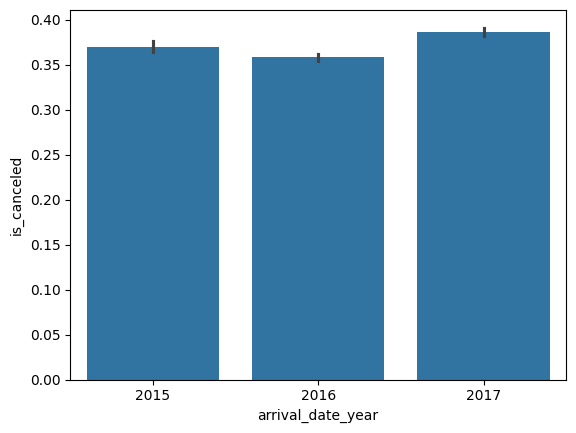
sns.displot(hotel_df['lead_time'])
# 예약 대기 기간에 따른 취소율 체크
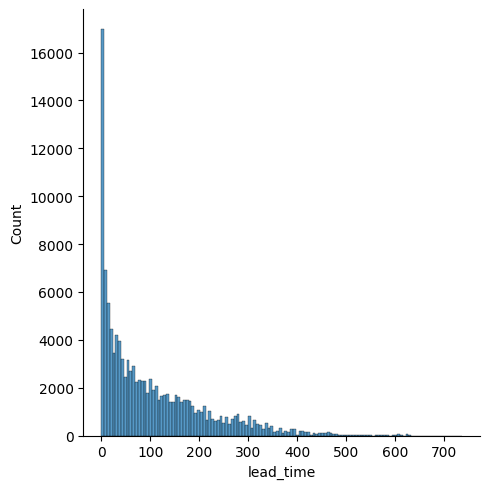
sns.barplot(x=hotel_df['distribution_channel'], y=hotel_df['is_canceled'])
# 예약 방법에 따른 취소율 체크
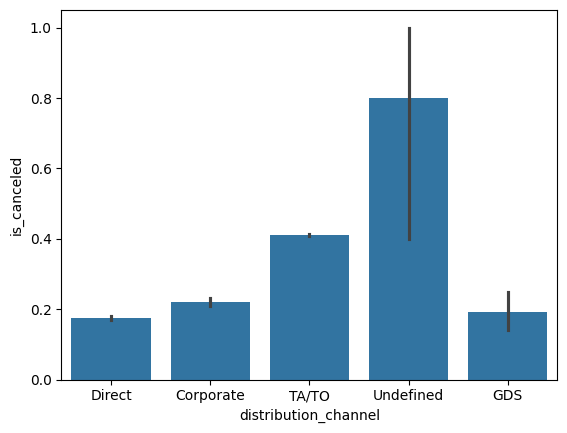
sns.barplot(x=hotel_df['hotel'], y=hotel_df['is_canceled'])
# 호텔 종류에 따른 취소율 체크
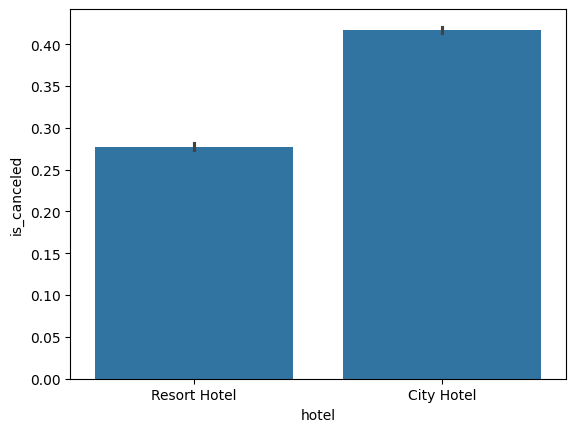
sns.barplot(x=hotel_df['arrival_date_year'], y=hotel_df['is_canceled'])
# 예약한 연도에 따른 취쇼율 차이 체크
import calendar
print(calendar.month_name[1])
print(calendar.month_name[2])
print(calendar.month_name[3])
print(calendar.month_name[4])
# January February March April
for i in range(1, 13):
months.append(calendar.month_name[i])
months
['January',
'February',
'March',
'April',
'May',
'June',
'July',
'August',
'September',
'October',
'November',
'December']
# corr() : 열들 간의 상관관계를 계산하는 함수. (피어슨 상관계수)
# -1 ~ 1 까지의 범위를 가지며 0에 가까울수록 두 변수의 상관관계가 없거나 매우 약함을 의미
plt.figure(figsize=(15,15))
sns.heatmap(hotel_df.corr(numeric_only=True), cmap='coolwarm', vmax=1, vmin=-1, annot=True)

# people 파생변수 생성
hotel_df['people'] = hotel_df['adults'] + hotel_df['children'] + hotel_df['babies']
hotel_df.head()
# people이 0인 아닌 경우만 남김
hotel_df =hotel_df[hotel_df['people']!=0]
# seoson 파생변수
# arrival_date_month를 참조하여 아래와 같이 생성
# 12, 1, 2: winter
# 3, 4, 5: spring
# 6, 7, 8: summer
# 9, 10, 11:fall
season_dic ={'spring' : [3, 4, 5], 'summer': [6, 7, 8], 'fall':[9, 10, 11], 'winter': [12, 1, 2]}
new_season_dic = {}
for i in season_dic:
for j in season_dic[i]:
new_season_dic[calendar.month_name[j]] = i
new_season_dic
# hotel_df['season'] = hotel_df['arrival_date_month'].apply(lambda x:'winter' if (x in ['December', 'January', 'February'])
# else ('spring' if (x in ['March', 'April', 'May'])
# else ('summer' if (x in ['June', 'July', 'August'])
# else 'fall')))
hotel_df['season'] = hotel_df['arrival_date_month'].map(new_season_dic)
# 원하는 방과 실제 방의 타입이 같은지 다른지 0과 1로 표기
hotel_df['expected_room_type'] = (hotel_df['reserved_room_type'] == hotel_df['assigned_room_type']).astype(int)
# string으로 들어간 데이터만 확인
obj_list = []
for i in hotel_df.columns:
if hotel_df[i].dtype =='O':
obj_list.append(i)
obj_list
for i in obj_list:
print(i, hotel_df[i].nunique())
hotel_df.drop(['country', 'arrival_date_month'], axis=1, inplace=True)
obj_list.remove('country')
obj_list.remove('arrival_date_month')
hotel_df = pd.get_dummies(hotel_df, columns=obj_list)
2. 앙상블(Ensemble) 모델
* 여러개의 머신러닝 모델을 이용해 최적의 답을 찾아내는 기법을 사용하는 모델
* 보팅(Voting)
* 서로 다른 알고리즘 model을 조합해서 사용
* 모델에 대해 투표로 결과를 도출
* 배깅(Bagging)
* 같은 알고리즘 내에서 다른 sample 조합을 사용
* 샘플 중복 생성을 통해 결과를 도출
* 부스팅(Boosting)
* 약한 학습기들을 순차적으로 학습시켜 강력한 학습기를 만듦
* 이전 오차를 보완해가면서 가중치를 부여
* 성능이 매우 우수하지만 잘못된 레이블이나 아웃라이어에대해 필요이상으로 민감
* AdaBoost, Gradient Boosing, XGBoost, LightGBM
* 스태킹(Stacking)
* 다양한 개별 모델들을 조합하여 새로운 모델을 생성
* 다양한 모델들을 학습시켜 예측 결과를 얻은 다음 다양한 모델들의 예측 결과를 입력으로 새로운 메타 모델을 학습
3. 랜덤 포레스트(Random Forest)
* 머신러닝에서 많이 사용되는 앙상블 기법 중 하나이며, 결정 나무를 기반으로 함
* 학습을 통해 구성해 놓은 결정 나무로부터 분류 결과를 취합해서 결론을 얻는 방식
* 성능은 꽤 우수한 편이나 오버피팅 하는 경향이 있음
* 랜덤 포레스트의 트리는 원본 데이터에서 무작위로 선택된 샘플을 기반으로 학습함
각 트리가 서로 다른 데이터셋으로 학습되어 다양한 트리가 생성되며 모델의 다양성이 증가함
* 각각의 트리가 예측한 결과를 기반으로 다수결 또는 평균을 이용하여 최종 예측을 수행함
* 분류와 회귀 문제에 모두 사용될 수 있으며 특히 데이터가 많고 복잡한 경우에 매우 효과적인 모델
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(hotel_df.drop('is_canceled', axis=1), hotel_df['is_canceled'], test_size=0.3, random_state=2024)
X_train.shape, X_test.shape, y_train.shape, y_test.shape
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(random_state=2024)
rf.fit(X_train, y_train)
pred1 = rf.predict(X_test)
pred1
array([1, 0, 0, ..., 1, 1, 1])proba1 = rf.predict_proba(X_test)
proba1
array([[0.06 , 0.94 ],
[0.54833333, 0.45166667],
[0.98 , 0.02 ],
...,
[0.49 , 0.51 ],
[0.06 , 0.94 ],
[0. , 1. ]])# 첫번째 테스트 데이터에 대한 예측 결과
proba1[0]
array([0.06, 0.94])# 모든 테스트 데이터에 대한 호텔 예약을 취소할 확률만 출력
proba1[:, 1]
array([0.94 , 0.45166667, 0.02 , ..., 0.51 , 0.94 ,
1. ])4. 머신러닝/딥러닝에서 모델의 성능을 평가하는데 사용하는 측정값
* Accuracy : 올바른 예측의 비율
* Precision : 모델에서 수행한 총 긍정 예측 수에 대한 참 긍정 예측의 비율
* Recall : 실제 긍정 사레의 총 수에 대한 참 긍정 예측의 비율
* F1 Score : 정밀도와 재현율의 조화 평균이며, 정밀도와 재현율 간의 균형을 맞추기 위한 단일 매트릭으로 사용
* AUC-ROC Curve : 참 양성률과 가 양성률 간의 균형을 측정
* AUC : ROC 커브와 직선 사이의 면적을 의미. 범위는 0.5 ~ 1 이며 값이 클수록 예측의 정확도가 높음
* ROC Curve : 이진 분류의 성능을 측정하는 도구. 민감도와 특이도 사이의 관계
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report, roc_auc_score
accuracy_score(y_test, pred1)
0.8643420646284287
confusion_matrix(y_test, pred1)
array([[20709, 1659],
[ 3173, 10078]])print(classification_report(y_test, pred1))
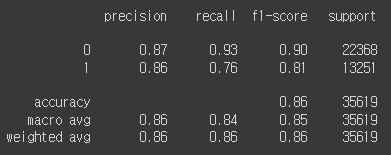
roc_auc_score(y_test, proba1[:, 1])
0.9315576511541386
# 하이퍼 파라미터 수정(max_depth = 30 적용)
rf2 = RandomForestClassifier(max_depth=30, random_state=2024)
rf2.fit(X_train, y_train)
proba2 = rf2.predict_proba(X_test)
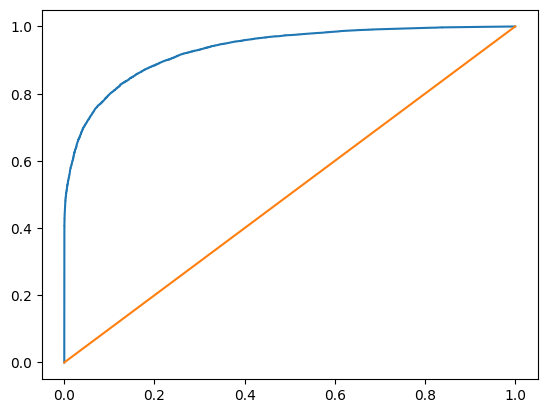
roc_auc_score(y_test, proba2[:, 1])
0.9319781899069026
import matplotlib.pyplot as plt
from sklearn.metrics._plot.roc_curve import roc_curve
fpr, tpr, thr = roc_curve(y_test, proba2[:, 1])
print(fpr, tpr, thr)
[0.00000000e+00 4.47067239e-05 4.47067239e-05 ... 9.30525751e-01 9.31419886e-01 1.00000000e+00] [0. 0.36465172 0.36517999 ... 0.99894348 0.99894348 1. ] [2.00000000e+00 1.00000000e+00 9.99767442e-01 ... 6.17283951e-05 3.15457413e-05 0.00000000e+00]
plt.plot(fpr, tpr, label = 'ROC Curve')
plt.plot([0, 1], [0, 1])
plt.show()
# 하이퍼 파라미터 추가 수정
# max_depth = 30 적용
# min_samples_split = 5 적용
# n_estimators = 70 적용
rf3 = RandomForestClassifier(min_samples_split=5, random_state=2024, max_depth=30, n_estimators=70)
rf3.fit(X_train, y_train)
proba3 = rf3.predict_proba(X_test)
roc_auc_score(y_test, proba3[:, 1])
5. 하이퍼 파라미터 최적의 값 찾기
* GridSearchCV: 원하는 모든 하이퍼 파라미터를 적용하여 최적의 값을 찾음
* RandomizedSearchCV: 원하는 하이퍼 파라미터를 지정하고 n_lter 값을 설정하여 해당 수만큼 random하게 조합하여 최적의 값을 찾음
from sklearn.model_selection import GridSearchCV, RandomizedSearchCV
params = {
'max_depth' : [30, 40, 50],
'min_samples_split' : [3, 5, 7],
'n_estimators' : [70, 120, 150]
}
rf4 = RandomForestClassifier(random_state = 2024)
grid_df = GridSearchCV(rf4, params) # cv : 데이터 교차 검증
grid_df.fit(X_train, y_train)
grid_df.best_params_
grid_df.cv_results_
rf5 = RandomForestClassifier(random_state = 2024)
rand_df = RandomizedSearchCV(rf5, params, n_iter=4, random_state=2024)
rand_df.fit(X_train, y_train)
rand_df.best_params_
rand_df.cv_results_
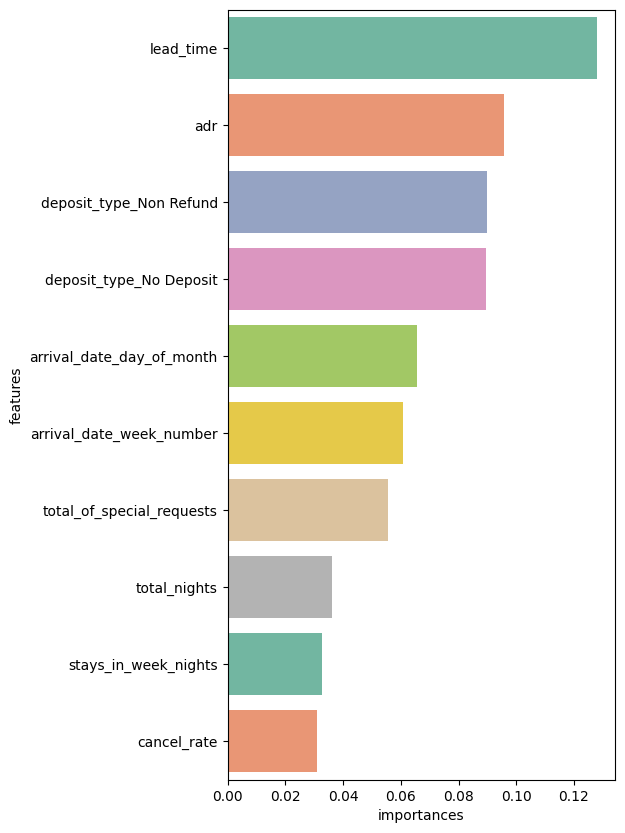
6. 피처 중요도 (Feature Importances)
* 결정 나무에서 노드를 분기할 때 해당 피처가 클래스를 나누는데 얼마나 영향을 미쳤는지 표기하는 척도
* 0에 가까우면 클래스를 구분하는데 해당 피처의 영향이 거의 없다는 것이며, 1에 가까우면 해당 피처가 클래스를 나누는데 영향을 많이 줬다는 의미
rf6 = RandomForestClassifier(random_state=2024, max_depth=40, min_samples_split=3, n_estimators=150)
rf6.fit(X_train, y_train)
proba6 = rf6.predict_proba(X_test)
roc_auc_score(y_test, proba6[:, 1])
0.9316574459006468proba6
array([[0.11200483, 0.88799517],
[0.53044444, 0.46955556],
[0.96666667, 0.03333333],
...,
[0.60166667, 0.39833333],
[0.04944444, 0.95055556],
[0. , 1. ]])
rf6.feature_importances_
array([1.27823051e-01, 2.15106897e-02, 6.08530338e-02, 6.56231673e-02,
2.18457194e-02, 3.26658278e-02, 9.84420098e-03, 5.24362470e-03,
7.92731535e-04, 1.64528429e-03, 2.29997289e-02, 2.88230691e-03,
2.02572330e-02, 2.26772762e-03, 9.57062769e-02, 2.07068228e-02,
5.55073952e-02, 1.23728476e-02, 3.63467496e-02, 2.90236557e-02,
3.11376863e-02, 6.76495945e-03, 6.07191041e-03, 6.89702660e-03,
1.37997322e-03, 5.36402653e-03, 4.61283329e-03, 1.08787793e-03,
2.79929352e-03, 7.58261231e-03, 2.29578249e-04, 1.05126162e-02,
0.00000000e+00, 5.24637263e-03, 7.64748681e-04, 6.23406908e-04,
3.49206823e-03, 2.06972837e-03, 1.07386134e-03, 9.79190777e-04,
3.08828771e-04, 2.58304355e-05, 9.22132027e-03, 1.13887810e-03,
9.73523759e-04, 4.70736878e-03, 2.39773229e-03, 1.41322456e-03,
1.04562217e-03, 3.91421067e-04, 6.72654170e-05, 6.61483390e-05,
8.57559071e-06, 8.96005631e-02, 9.00179693e-02, 5.85978513e-04,
2.63186282e-03, 3.93763157e-04, 1.53764252e-02, 1.13568115e-02,
5.18292064e-03, 6.11591793e-03, 6.96445996e-03, 5.39974249e-03])
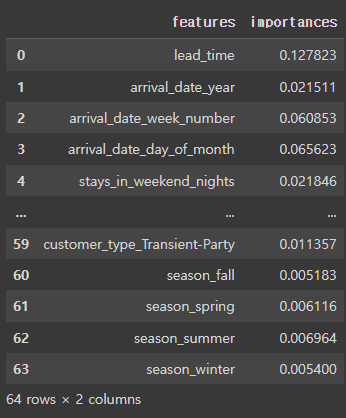
feature_imp = pd.DataFrame({
'features' : X_train.columns,
'importances' : rf6.feature_importances_
})
feature_imp
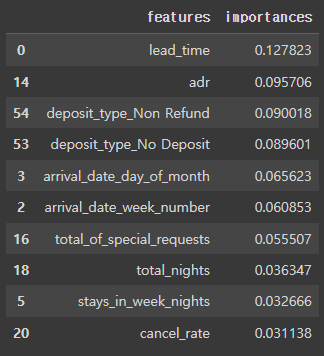
top10 = feature_imp.sort_values('importances', ascending=False).head(10)
top10
plt.figure(figsize=(5,10))
sns.barplot(x='importances', y='features', data=top10, palette='Set2')
'딥러닝과 머신러닝' 카테고리의 다른 글
| 여러 모델 적용 후 성능 확인하기 (2024-06-18) (0) | 2024.06.18 |
|---|---|
| lightGBM (2024-06-18) (0) | 2024.06.18 |
| Scaling, Normalization, Support Vector Machine (2024-06-12) (0) | 2024.06.17 |
| Logistic Regression(2024-06-12) (1) | 2024.06.12 |
| Linear Regression, MSE, MAE, RMSE(2024-06-11) (0) | 2024.06.11 |



