1. Clusters(클러스터)
* 유사한 특성을 가진 개체들의 집합
* 고객 분류, 유전자 분서그 이미지 분할
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import make_blobs
# 100개의 행, 3개의 정답(종속변수의 클래스가 3개로),
X, y = make_blobs(n_samples=100, centers=3,random_state=2023)

from sklearn.cluster import KMeans
km = KMeans(n_clusters = 5)
km.fit(X)
pred = km.predict(X)
sns.scatterplot(x=X[0], y=X[1], hue=pred)
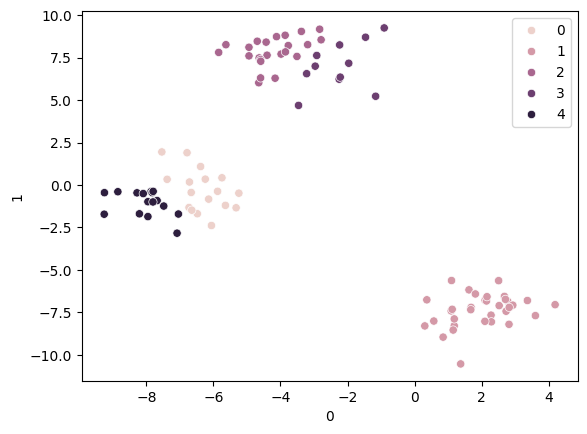
# 평가값: 하나의 클러스터안에 중심점으로부터 각각의 데이터 거리를 합한 값의 평균
km.inertia_
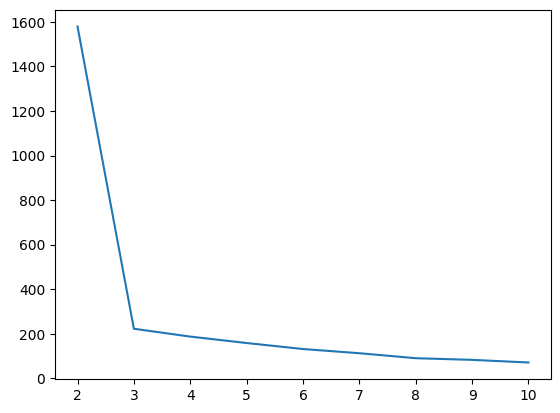
inertia_list = []
for i in range(2, 11) :
km = KMeans(n_clusters = i)
km.fit(X)
inertia_list.append(km.inertia_)
inertia_list
[1578.856698952461,
222.7636237762,
187.54774629439763,
158.76742651218515,
131.78847258731062,
112.99110720239317,
90.630319593476,
83.1699210745245,
71.44672206928925]sns.lineplot(x=range(2, 11), y=inertia_list) # 엘보우 메서드
2. marketing 데이터셋
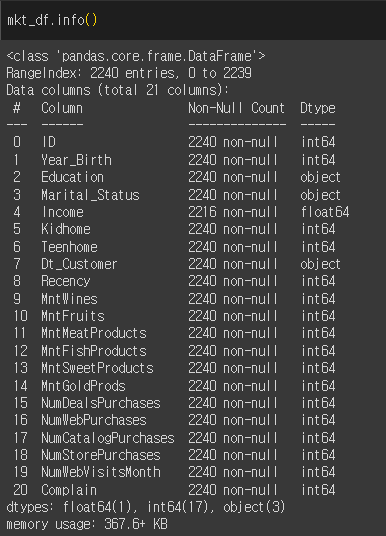
mkt_df = pd.read_csv('/content/drive/MyDrive/KDT 국비지원/6. 머신러닝과 딥러닝/Data/marketing.csv')
mkt_df
# Income 666666 데이터만 지우려고 할 때
# mkt_df = mkt_df[mkt_df['Income'] < 200000] NaN 값 데이터도 모두 삭제됨
mkt_df = mkt_df[mkt_df['Income'] !=666666]
mkt_df['Dt_Customer'] = pd.to_datetime(mkt_df['Dt_Customer'], format='%d-%m-%Y')
# 마지막으로 가입된 사람을 기준으로 데이터의가입 날짜(달)의 차를 구하기
# pass_month
mkt_df['pass_month'] = (mkt_df['Dt_Customer'].max().year * 12 + mkt_df['Dt_Customer'].max().month) - (mkt_df['Dt_Customer'].dt.year * 12 + mkt_df['Dt_Customer'].dt.month)
# 와인 + 과일 + 육류 + 어류 + 단맛 + 골드
# Total_Mnt
mkt_df['Total_Mnt'] = mkt_df[['MntWines','MntFruits', 'MntMeatProducts', 'MntFishProducts', 'MntSweetProducts', 'MntGoldProds']].sum(axis=1)
mkt_df.head()
# 결혼 여부 수정
mkt_df['Marital_Status'] = mkt_df['Marital_Status'].replace({
'Married' : 'Partner',
'Together' : 'Partner',
'Single' : 'Single',
'Divorced' : 'Single',
'Widow' : 'Single',
'Alone' : 'Single',
'Absurd' : 'Single',
'YOLO' : 'Single'})
mkt_df = pd.get_dummies(mkt_df, columns=['Education', 'Marital_Status'])
mkt_df
from sklearn.preprocessing import StandardScaler
ss= StandardScaler()
ss.fit_transform(mkt_df)
ss_df = pd.DataFrame(ss.fit_transform(mkt_df), columns = mkt_df.columns)
ss_df
3. KMeans
* k개의 중심점을 찍은 후에 이 중심점에서 각 점간의 거리의 합이 가장 최소가 되는 중심점 k의 위치를 찾고, 이 중심점에서 가까운 점들을 중심점을 기준으로 묶는 알고리즘
* k개의 클러스터의 수는 정해줘야 함
inertia_list = []
for i in range(2,11):
km = KMeans(n_clusters = i, random_state=2024)
km.fit(ss_df)
inertia_list.append(km.inertia_)
sns.lineplot(x=range(2,11), y=inertia_list)

4. 실루엣 스코어(Silhouette Score)
* 군집화의 품질을 평가하는 지표로, 각 데이터 포인트가 자신이 속한 군집과 얼마나 잘 맞는지, 그리고 다른 군집과 얼마나 잘 구분되는지를 츨정하는 평가지표
* -1 ~ 1 사이의 값을 가지며 값이 클수록 군집화의 품질이 높음을 나타냄
from sklearn.metrics import silhouette_score
score = []
inertia_list = []
for i in range(2,11):
km = KMeans(n_clusters = i, random_state=2024)
km.fit(ss_df)
pred = km.predict(ss_df)
score.append(silhouette_score(ss_df, pred))
sns.lineplot(x=range(2,11), y=score)

km= KMeans(n_clusters = 4, random_state=2024)
km.fit(ss_df)
pred = km.predict(ss_df)
mkt_df['label'] = pred
mkt_df['label'].value_counts()
label
1 975
2 598
3 588
0 54
Name: count, dtype: int64
'딥러닝과 머신러닝' 카테고리의 다른 글
| Pytorch로 구현한 논리회귀 (2024-06-20) 미완성 (0) | 2024.06.20 |
|---|---|
| Pytorch 선형회귀(2024-06-19) (1) | 2024.06.20 |
| 여러 모델 적용 후 성능 확인하기 (2024-06-18) (0) | 2024.06.18 |
| lightGBM (2024-06-18) (0) | 2024.06.18 |
| Random Forest, 하이퍼파라미터, Feature Importances (0) | 2024.06.17 |



