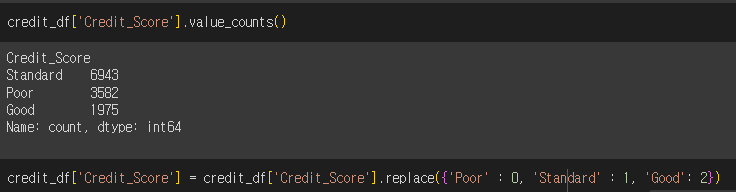
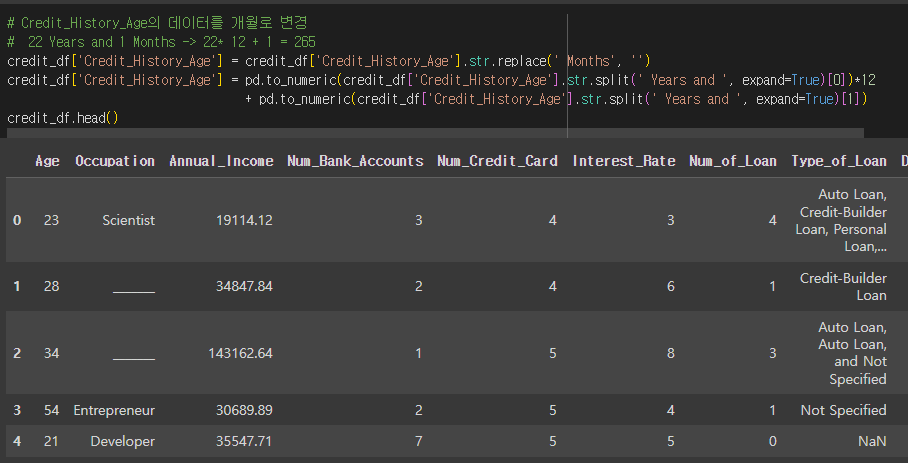
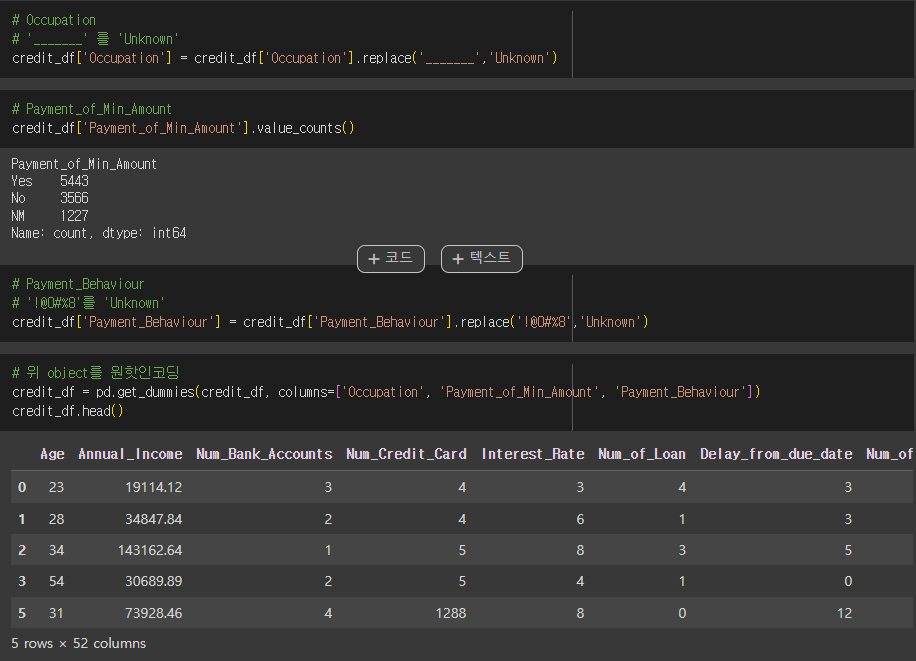
1. credit 데이터셋
credit_df = pd.read_csv('/content/drive/MyDrive/KDT 국비지원/6. 머신러닝과 딥러닝/Data/credit.csv')
credit_df
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns





2-1. 리프 중심 히스토그램 기반 알고리즘
* 트리를 균형적으로 분할하는 것이 아니라, 최대한 불균형하게 분할하는 방식
* 특성들의 분포를 히스토그램으로 나타내고, 해당 히스토그램을 이용하여 빠르게 후보 분할 기준을 선택
* 후보 분할 기준 중에서 최적의 분할 기준으로 선택하기 위해, 데이터 포인트들을 히스토그램에 올바르게 배치하고 이를 이용하여 최적의 분할 기준을 선택

히스토그램 - 데이터의 분포도를 나타내는 그래프
2-2. GBM(Gradient Boosting Model)
* 순차적으로 모델을 학습시키는 방법
* 첫 번째 모델을 학습시키고 두 번째 모델은 첫 번째 모델의 오류를 학습하는 식으로 진행(이런 방식으로 각 모델이 이전 모델의 오류를 보완하는 형태)
* 부스팅에서는 각 데이터 포인트에 가중치를 부여함. 초기에는 모든 데이터 포인터에 동일한 가중치를 부여하지만, 이후 모델이 학습되면서 잘못 예측된 데이터 포인트의 가중치를 증가시켜 다음 모델이 이 데이터 포인트에 더 주의를 기울이도록 함
* 트리가 모두 학습된 후 예측 결과를 결합하여 최종 예측을 만드는데 일반적으로 분류 문제에서는 다수결 투표 방식으로, 회귀 문제에서는 예측값의 평균을 사용
2-3. 부스팅 모델의 주요 개념
* 약한 학습기(Weak Learner) : 단독으로는 성능이 좋지 않은 간단한 모델(주로 깊이가 얕은 결정 트리, 깊이가 1인 매우 간단한 학습기)을 사용
* 약한 학습기를 순차적으로 학습시키고 그 다음에는 첫 번째 학습기의 오류를 보완하는 두 번째 학습기를 학습시킴
from sklearn.model_selection import train_test_split
from lightgbm import LGBMClassifier
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report, roc_auc_score
X_train, X_test, y_train, y_test = train_test_split(credit_df.drop('Credit_Score', axis=1), credit_df['Credit_Score'], test_size=0.2, random_state=2024)
X_train.shape, y_train.shape, X_test.shape, y_test.shape
base_model = LGBMClassifier(ramdom_state=2024)
base_model.fit(X_train, y_train)
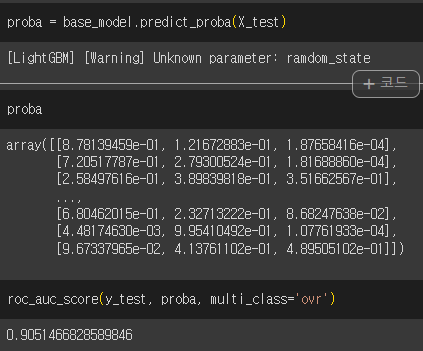
pred = base_model.predict(X_test)

'딥러닝과 머신러닝' 카테고리의 다른 글
| KMean, Silhouette Score (2024-06-18) (0) | 2024.06.18 |
|---|---|
| 여러 모델 적용 후 성능 확인하기 (2024-06-18) (0) | 2024.06.18 |
| Random Forest, 하이퍼파라미터, Feature Importances (0) | 2024.06.17 |
| Scaling, Normalization, Support Vector Machine (2024-06-12) (0) | 2024.06.17 |
| Logistic Regression(2024-06-12) (1) | 2024.06.12 |



