1.판다스(Pandas)
* 데이터 분석을 위한 파이썬 라이브러리 중 하나로, 표 형태의 데이터나 다양한 형태의 데이터를 쉽게 처리하고 분석할 수 있다
* 데이터 프레임(DataFrame)이라는 자료 구조를 제공한다
!pip install pandas
import pandas as pd
# 코랩엔 기본 설치되어 있음
2-1. Series
* Series는 1차원 배열과 같은 자료구조로 하나의 열을 나타낸다
* Series의 각 요소는 인덱스(index)와 값(value)으로 구성되어 있다
* 값은 넘파이의 ndarray 기반으로 저장됨
* Series는 다양한 데이터 타입을 가질 수 있으며 정수, 실수, 문자열 등 다양한 형태의 데이터를 담을 수 있다

2-2. DataFrame
* DataFrame은 pandas 라이브러리에서 제공하는 중요하고 강력한 데이터 구조로 2차원의 테이블 형태 데이터를 다루는 자료구조
* DataFrame의 각 요소는 인덱스(index), 열(column), 값(value)으로 구성되어 있음
* DataFrame은 행과 열로 이루어져 있으며, 각 열은 다양한 데이터 타입을 가질 수 있음
* 값은 넘파이의 ndarray 기반으로 저장


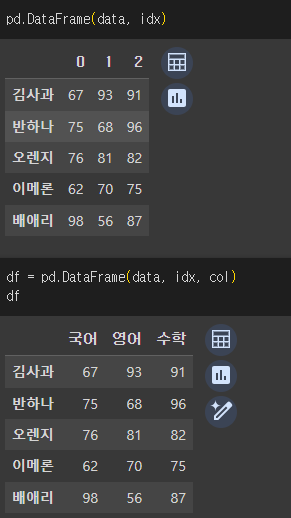
2-3. 딕셔너리를 사용하여 데이터프레임을 생성하기

3. CSV 파일 읽어오기
* csv(Comma Separated Value)의 약자로 데이터를 쉼표로 구분한 파일

4. 데이터프레임 기본정보 알아보기



# 정렬하기
df.sort_index() # index로 오름차순 정렬
df.sort_index(ascending=False) # index로 내림차순 정렬
df.sort_values(by='height', ascending=False) # 키로 내림차순 정렬
df.sort_values(by='height', ascending=False, na_position='first') # 키로 내림차순 정렬 nan값 상단으로 고정
df.sort_values(by=['height', 'brand'], ascending=[False, False]) # 1차 정렬 : 키(내림차순), 2차 정렬 : 브랜드(내림차순)
5. 데이터 다루기
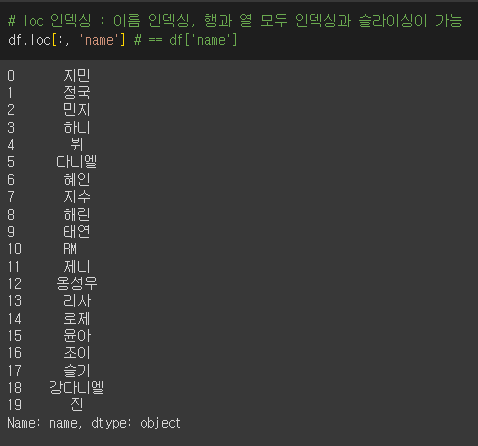

# iloc 인덱싱 : index로 인덱싱, 행과 열 모두 인덱싱과 슬라이싱이 가능
df.iloc[:,0] # 행은 모두 열은 0번(name)만
df.iloc[:,[0,2]] # 행은 모두 열은 0,2번만
df.iloc[:,0:2] # 행은 모두 열은 0,1번만
df.iloc[1:5,0:2] # 행은 1~4번 열은 0~1번





6. 결측값(Null, NaN)
* 비어있는 값, 판다스에서는 NaN로 표기 된 것은 모두 결측값으로 취급


# fillna(): 결측값을 채워주는 함수
df['height'].fillna(0) # 결측값을 0으로 채우고 보여줌
# df['height'].fillna(0, inplace=True) # 결측값을 0으로 채우고 저장함

df_copy의 height의 NaN 값에 height의 평균 값을 채워줌


7. 행, 열 추가 및 삭제하기
* 행을 추가할 때 dict 형태의 데이터를 만들고 append() 메서드를 사용하여 데이터를 추가
* ignore_index=True 옵션을 추가해야 에러가 발생하지 않는다





8. 통계함수


9.그룹



'데이터 분석' 카테고리의 다른 글
| Matplotlib (2024-05-27) (0) | 2024.05.27 |
|---|---|
| Pandas, Series, DataFrame 2 (2024-05-24 (1) | 2024.05.27 |
| Numpy (2024-05-22) (0) | 2024.05.22 |
| 과제 여러개 파일 수집 (2024-05-22) (0) | 2024.05.22 |
| selenium, xpath (2024-05-21) (0) | 2024.05.21 |



